INSet Interfaces Hierarchy
In This Topic
NOV Data Structures are based on the Sets Theory. The term "set" in the context of NOV Data Structures, should be understood as a "finite set" as collections/maps/trees/graphs do not deal with "infinite sets" in general. Fundamentally NOV Data Structures are implementing three types of interfaces
- Basic operations interfaces
- Iteration interfaces - see Iterators for info.
- INSet<T> - derived interfaces
Basic Operations Interfaces
The basic operations interfaces define cornerstone methods or properties, that INSet<T>-derived interfaces reuse via interface inheritance. Although primary intended for NOV Data Structures, the general and simple nature of these interfaces, allows them to be used by other NOV modules (such as Graphics, Layout etc.). The basic operations interfaces are declared as follows:
| Basic Operations Interfaces |
Copy Code
|
// Implemented by objects that can be threated as finite or infinite sets of specific items.
public interface INContains<T>
{
// Queries whether the specified item is contained in this object.
bool Contains(T item);
}
// Implemented by objects that can provide a count for a specific type of items.
public interface INCountable<T>
{
// Gets the count of items
int Count { get; }
}
// Implemented by objects in which you can add items from a specific type.
public interface INAddable<T>
{
// Adds the specified item
void Add(T item);
}
// Implemented by objects from which you can remove items from a specific type.
public interface INRemovable<T>
{
// Removes the specified item
void Remove(T item);
}
// Implemented by objects from which you can remove all content (items).
public interface INClearable
{
// Removes all content (items)
void Clear();
}
|
INSet<T> Interfaces Hierarchy
The following image illustrates the INSet derived interfaces:
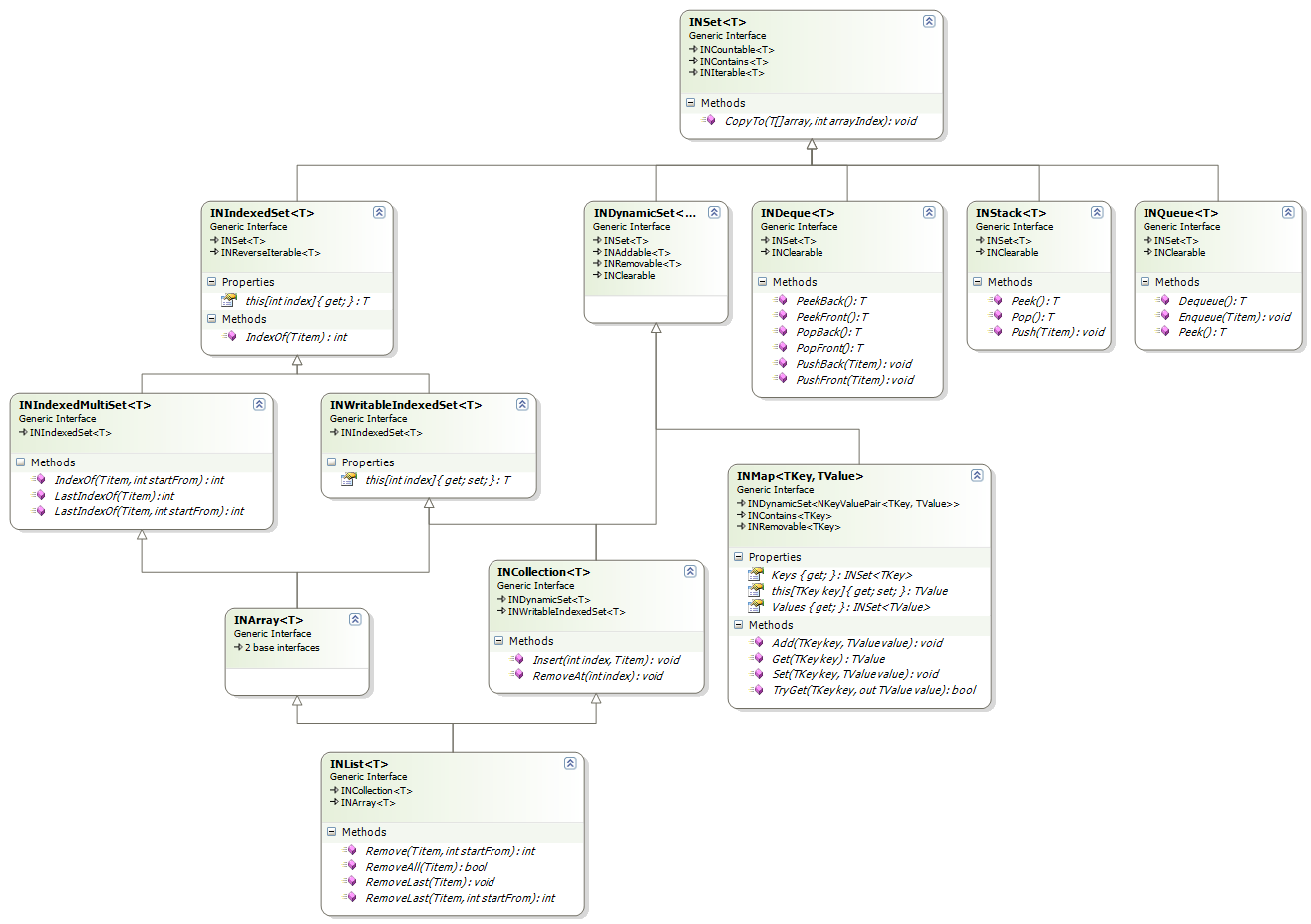
The INSet<T> derived interfaces are logically separating the sets by the following abilities:
- ability for random access - sets in which you can randomly access items at specific index (INIndexedSet<T>).
- ability for dynamic mutation - sets to which you can add items and remove items from (INDynamicSet<T>).
- ability to replace items - sets in which you can replace items at a specific index (INWritableIndexedSet<T>).
- ability to contain duplicate items - in the Sets Theory such sets are called multisets. In NOV we are primary interested in multisets that support random access (INIndexedMultiSet<T>), in order to define IndexOf/LastIndexOf operations.
Following are comments about the interfaces in the INSet<T> hierarchy:
| Interface |
Description |
| INSet<T> |
Serves as base for all fundamental interfaces in NOV Data Structures. Represents a finite set of items of a specific type. Defines the three most common operations with finite sets: containment query, count query and iteration (by deriving from the respective basic interfaces). An important ability of all INSet<T> implementations is the ability to copy the items contained in the set to a CLR array (via the INSet<T>.CopyTo method). A common implementation pattern for all concrete implementation of INSet<T> is that you can construct it from another INSet<T> or INIterator<T>.
|
| INDynamicSet<T> |
Represents a set, in which you can add items and remove items from. Because the items of a set can be enumerated, and because INDynamicSet<T> supports removal of specific items, it naturally derives from the INClearable interface. Note that by itself, the dynamic set does not support indexed access, so the Add operation does not necessarily add the item to the end of the set. |
| INIndexedSet<T> |
Represents a set, the items of which can be accessed at random indices. This naturally leads to the indexed order of the items - hence the INIndexedSet<T> adds support for reverse items iteration, by deriving from INReverseIterable<T>. When implemented by it's own (i.e. not as part of an INIndexedMultiSet<T> implementation), the items in an indexed set are unique. |
| INWritableIndexedSet<T> |
Represents an indexed set, the items of which can be substituted at random indexes. |
| INIndexedMultiSet<T> |
Represents an indexed set, that may contain duplicate items. Extends the base INIndexedSet<T> with methods for querying the next occurrence of a specific item, as well as with methods for occurrence queries in reverse order (last-to-first) |
| INArray<T> |
Represents a writable indexed multiset. For example the .NET one dimensional generic array has the features of an INArray<T> - you can wrap any .NET one dimensional generic array as an INArray<T>. (see CLR Interop for an example). |
| INCollection<T> |
Represents a dynamic, writable, indexed set. When implemented by it's own (e.g. not as part of an INList implementation), the items in a collection are unique. |
| INList<T> |
Represents a collection in which items can appear multiple times. It combines the features of INCollection<T> and INIndexedMultiSet<T> and extends them with methods for first and last occurrence removal. See Lists, Deques, Stacks and Queues. |
| INDeque<T> |
Represents a set, with double-ended queue access (provides access and modifications to both its head and tail) - see Lists, Deques, Stacks and Queues. |
| INStack<T> |
Represents a set, with LIFO (Last-In First-Out) items access - see Lists, Deques, Stacks and Queues. |
| INQueue<T> |
Represents a set, with FIFO (First-In First-Out) items access - see Lists, Deques, Stacks and Queues. |
| INMap<T> |
Represents a dynamic set of key-value pairs, where the keys in the set are unique - i.e. a mapping of distinct keys to values - see Maps and Unique Sets. |