In NOV the abstraction of a "document" is represented by the NDocument abstract class, that is a direct descendant of the NDocumentNode abstract class which on its turn derives from the NNode class.
Documents are node hierarchies that are constructed from a specific set of node types. Documents are structurally organized in two distinct subtrees - content and styling. In this way the concept of separating the content from its styling is fundamentally implemented by all documents. Documents provide its content subtree with additional features and services, such as:
- Expressions - expressions can be used to assign dynamic property values to elements, that can be a function of one or more other element:property values. In this way the content of documents can implement complex functional bindings.
- Measure and Arrange - the measure and arrange of documents aims to provide specific elements with the ability to perform incremental layouts.
- Support for Undo/Redo - documents are designed to be visually edited and the support for undo/redo is an essential feature of each editable type of document.
Documents are designed to contain other documents. This means that NOV has built-in support for compound documents.
Specific types of documents are usually associated with each type of specific content that needs to take advantage of the higher level DOM services that documents provide.
The following image illustrates the class hierarchy of the core nodes types that construct a DOM document.
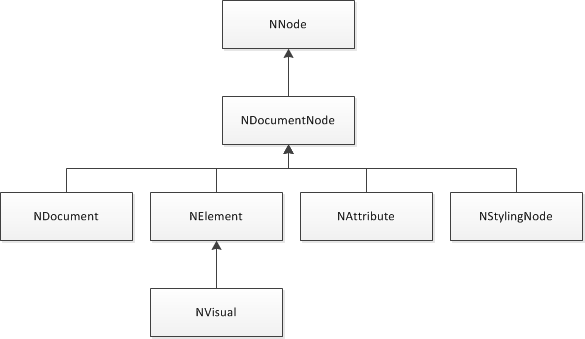
figure 1. Document Nodes Class Hierarchy
Following is a brief overview of the core types of nodes.
NNode
Serves as base class for all nodes. Performs core hierarchical and meta data information management. See Nodes for more info.
NDocumentNode
Serves as base class for all types of nodes that are intended to reside in a DOM document. Each NDocumentNode instance knows about the document in which it resides and also has build-in support for history. Since NDocumentNode sits pretty low in the DOM nodes class hierarchy, this means that every user or programmable action executed towards a DOM hierarchy can potentially be recorded by the document history service.
NDocument
Represents a DOM document and serves as base class for all DOM documents. The primary function of a document is to provide the elements hierarchy hosted by it with styling, deferred evaluation and history services. Embedded documents typically reside in the property dimension of elements. Documents, the elements of which contain other documents are called compound documents. The document features are described in details in this topic.
NElement
Serves as base class for all elements that are used to model the elements hierarchy of a specific type of document. Elements are uniquely identifiable in the scope of their document. Elements fundamentally differ from other types of document nodes, in the fact that their property system is modified to support computed values (see Properties). Certain elements can participate in the document Measure and Arrange system.
NVisual
A special type of element that can participate in the DOM visual tree. Adds core support for transformations, clipping, painting and hit-testing. (see The Visual Tree for more information).
NAttribute
Serves as base class for document nodes that are designed to reside in the property dimension of an element. Typical examples of attributes are the NFill, NStroke and NShadow attributes (discussed in the Painting topic). Attribute sub-hierarchies are usually constructed by other attributes. This allows the attributes that reside in the property dimension of a specific owner element to notify the owner element whenever they change. Elements are designed to consume changes in the owned attribute sub-hierarchy as a single property change. Attributes generally do not care about the element, which owns them and elements generally do not care whether they own a specific attribute. A notable example of this behavior is for example the background fill of a widget - it becomes the computed value of an element via CSS - the fill is actually owned by the CSS declaration, but the element consumes the fills without caring about that fact.
NStylingNode
Serves as base class for all types of nodes that are used to construct the style sheets of a DOM document. Its main purpose is to invalidate the document cascade whenever changes in the document styling occurs. You will usually not derive from this type of node, but rather use the already defined types of styling nodes that are used to construct the CSS of a document. The DOM CSS is explained in details by the Styling and Inheritance topic.
The following image illustrates the structural organization of a DOM document.
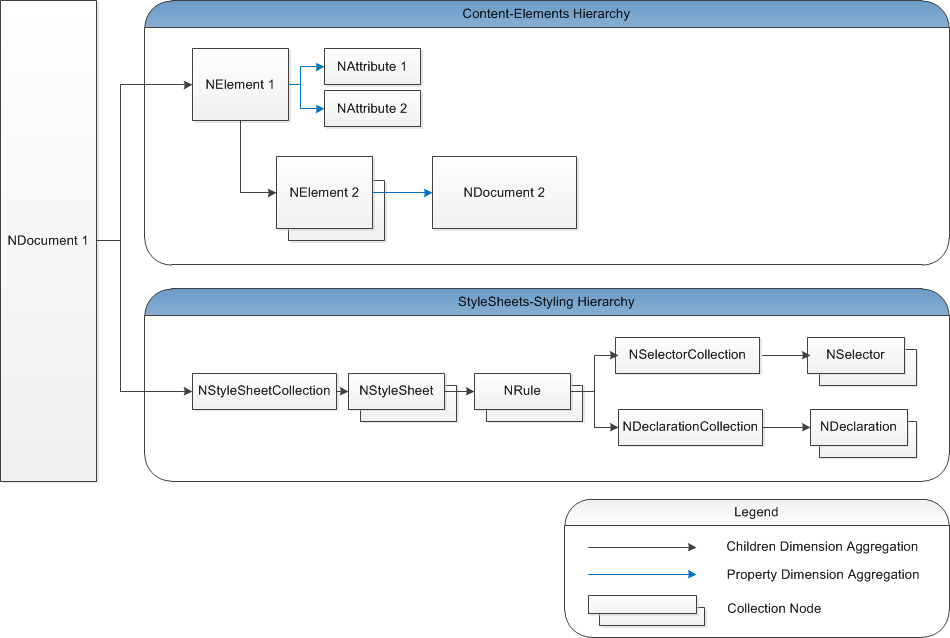
figure 2. Document Nodes Object Diagram
As you can see from the image above, documents are primarily divided into content and styling subtrees.
The content subtree is constructed by elements, that are rooted by a specific type of element, accessible from the NDocument-GetDocumentElement() method. In practice you will work with different subclasses of the NGenericDocument<TContent> class the Content property of which allows you to access the root element of the specific type of document. Elements are typically containing only other elements in their children dimension. Nodes aggregated by elements in the property dimension are typically either attributes or other documents. In figure 2 you can see that NAttribute 1 and NAttribute 2 reside in the property dimension of NElement 1.
Certain elements can aggregate other documents in their property dimension - in figure 2 you can see that NDocument 2 is aggregated in the property dimension of NElement 2. Such documents are called embedded documents. Embedded documents can inherit style sheets and history from the document that owns them. The documents embedded in a certain document are accessible via the NDocument-GetEmbeddedDocuments() method.
The styling subtree of a document consists of style sheets that contain styling rules. The purpose of the styling subtree is to define the rules that apply property values to specific elements that reside in the document content subtree. All nodes that reside in the styling subtree are derived from the NStylingNode base class, in order to invalidate the document styling cascade whenever the style sheets of a document have changed. The DOM styling is described in detail by the Styling and Inheritance topic.
Documents provide its content subtree with deferred evaluation services. The document evaluation is performed by the NDocument-Evaluate() method. You will rarely need to call this method directly, since document evaluation is in most cases automatically performed at regular intervals of time.
Between calls of the NDocument-Evaluate() method, the document automatically collects information about the elements whose expressions, styles and/or measure, arrange, display have been invalidated (marked as dirty). This information is internally stored in different evaluation pools and is later processed by certain steps of the document evaluation algorithm. This means that the document as an evaluation structure has deferred evaluation and is ready for display only after it has been evaluated.
The evaluation algorithm consists of several steps that may be subsequently repeated. The internal repetition of the evaluation algorithm is called an evaluation pass and is automatically performed, if after the previous evaluation pass the document contains dirty evaluation pools (i.e. there are elements whose expressions, styles, measure, arrange or display still remain dirty). The maximum count of evaluation passes can be controlled by the NDocument - MaxEvaluationPasses property.
Following is a detailed description of the steps performed by the evaluation algorithm.
1. Property Values Calculation
The purpose of this step is to calculate the local values of element properties that are specified by expressions, and to calculate the computed values of the elements properties that are marked as styleable or inheritable.
During this step the document first evaluates the element expressions and assigns the calculated values to the properties targeted by these expressions. Since expressions can generally generate cyclic dependencies, the expression calculation may be performed multiple times, until there are dirty expressions. The document MaxExpressionCycles property controls the maximum number of such repetitions. See Expressions for more info.
After all expressions have been calculated, the document calculates the computed values of the elements properties that are marked as stylable or inheritable, by taking into account the rules defined in the document style sheets. See Styling and Inheritance for more info.
After this step is performed the document is ready to perform the higher level steps of the evaluation algorithm, since it has a valid snapshot of the element computed (effective values).
2. Measure and Arrange
In between document evaluations and during the Property Values Calculation step the document accumulates the elements whose properties that are marked as affecting the element measure or arrange have changed. The document measure and arrange step aims to callback these elements and validate their measure and arrange - i.e. remeasure and rearrange them in order to be ready for display.
In order to participate in the document measure system, an element must implement the INMeasureElement interface. For such elements you can use property markup to define the properties that affect the element measure or simply call their InvalidateMeasure() method to mark the element for measure validation. During the measure phase the document calls the ValidateMeasure(NLayoutVisitor visitor) method of dirty measure elements in a leafs-to-root order - i.e. first measure the children and them measure the parent.
Similarly, in order to participate in the document arrange system, an element must implement the INArrangeElement interface. For such elements you can use property markup to define the properties that affect the element arrange or simply call their InvalidateArrange() method to mark the element for arrange validation. During the arrange phase the document calls the ValidateArrange(NLayoutVisitor visitor) method of dirty measure elements in a root-to-leafs order - i.e. first arrange the parent and them arrange the children.
The measure phase has the meaning of determining the desired size that elements want to take in their parents. Because such measurements are usually dependent on the measures of children, this phase is performed in a leafs-to-root order. Similarly the arrange phase has the meaning of final layout of elements and is therefore performed in a root-to-leafs order - i.e. it is parent elements that finally decide the arrangement of their children, based on the measures they have provided during the measure phase.
In certain circumstances the element measure depends on the element arrange. This introduces a cyclic dependency in the measure and arrange system that the document tries to resolve by repeating the measure and arrange step, until no elements are marked as measure or arrange invalid. The maximum count of such repetitions can be controlled by the document MaxMeasureArrangeCycles property.
After this step is performed the document is ready to be displayed.
3. Display Validation
Redrawing your entire document each time a document is evaluated is computationally expensive. That is why documents are designed to be redrawn in a very optimized manner, that includes rendering on multiple threads, dynamic rasterization and advanced caching techniques.
The final document evaluation step aims to reduce the computational effort needed to redraw the document. The display validation is something you will almost never have to think about, since in most cases you will derive elements from the NVisual class (or uses elements that already derive from this class).
As a NOV DOM developer however you will only have to mark the properties that affect the element display, so that the DOM knows that it needs to redraw a specific element when its property value has changed. See Visual Trees for more info.